本文共 8765 字,大约阅读时间需要 29 分钟。
该篇写的偏理论,点击
phpstudy的mysql目录介绍
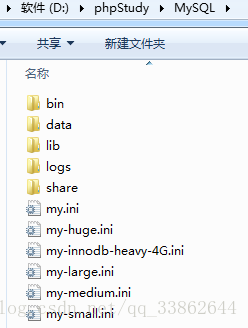
1、bin //可执行文件
2、data //数据库
3、lib //扩展库,一般用不到
4、logs //日志
5、share //系统需要的东西,如 编码啥的
6、my.ini //配置文件。linux上是my.cnf
剩余的ini文件也都是配置文件,只是针对的服务器配置不同而已,如 my-smail.ini是针对内存小于64M用的,用法如下:
假如你的服务器配置小于64M,将my-smail.ini文件改名为my.ini,然后将其他的配置文件删除即可
*默认路径:/usr/local/mysql/var
mysql> show variables like 'general_log_file'; #日志文件路径mysql> show variables like 'log_error'; #错误日志文件路径mysql> show variables like 'slow_query_log_file'; #慢查询日志文件路径
7、
sql语句的书写规则:
1、以分号结尾 可以用delimiter修改
2、不区分大小写
3、#或--注释
位、字节、字符(计量单位)的关系:
| 位 | 字节 | 字符(多字节) | |
| 英文、数字 | 8 | 1 | 1 |
| 汉字gbk编码 | 8 | 2 | 1(gbk中2个字节是1个字符) |
| 汉字utf8编码 | 8 | 3 | 1(uf8中3个字节是1个字符) |
mysql数据类型介绍:
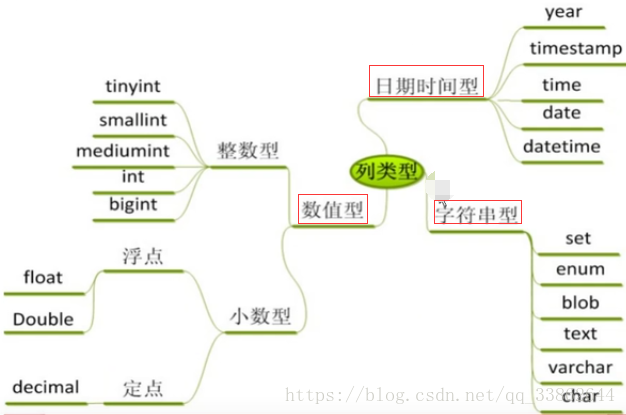
整数型:
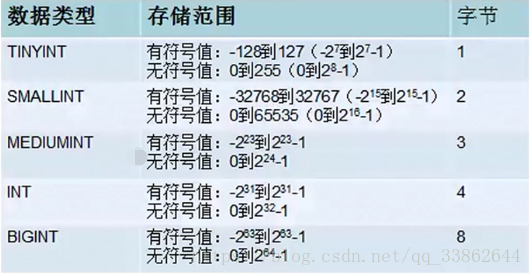
注意:有符号是从负数开始存,无符号是从正数0开始存;超过了最大值以最大值为准

注意:单双精度会四舍五入,和钱沾边的用decimal
字符串
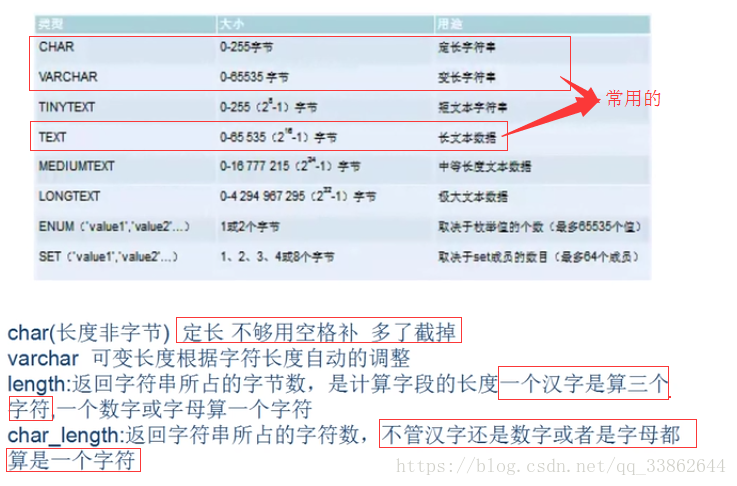
注意:
1、括号里的是长度是字符。select char_length(name) from tp5_user; //该字段中,字符串所占的字符数
2、char 读写速度快,因为他在内存中是按快找,缺点 浪费内存,因为存的不够会自动补空格
时间日期

*datetime的默认值是 '1970-01-01 00:00:00'
*timestamp的默认值是0,详见
字段的其他修饰关键词:
1、unsigned #无符号
2、auto_increment #自增
3、default 默认值 #给默认值的,如 价格默认0.00。不写 默认为null
4、comment '' #字段说明(注释)
5、not null #不能为空
6、null #可以为空
7、unique #唯一索引(对该列数据进行唯一性效验,插入重复的值会报error:Duplicate entry '123' for key 'user_name')
8、key 或 index #普通索引
9、primary key #主键索引

注意:
1、一般auto_increment 和 primary key是一对,在一起不分离 主键索引才自增
主键索引才自增
2、全文索引用的是MyISAM引擎,只支持英文
3、外键索引语法:foreign key (b表字段名) references a表(外键字段名)
如 a(外键)表是学生表,b(本)表是成绩表。
作用:a表中如果没有该id,b表插入不进去,保持了数据的一致性,如果想要删除a表中的数据,也是无法清空的,因为b表对a表有依赖性。
注意:数据不一致,俩个表的id数据不一致,就是b表中的id在a表中没有,会报1452;俩个id的数据类型、长度等不一致报1215
3.1、a表的id要和b表的user_id数据类型,有无符号,是否为空等完全一致。
速记:涉及数字加unsigned ,每列必加not null和commet ''
加索引的2种方式:1、在字段中加;2、所有字段书写完后统一加
SQL语句
sql语句中的运算符:
1、 = #2个意思,等于 或 赋值,系统会根据上下文判断
2、!= <> #不等于
3、< > <= >= #小于 大于 小于等于 大于等于
4、OR #或
5、AND #与
6、BETWEEN ... AND #在...之间(判断2-5范围,与的关系)
7、IN #在...之内(判断2,3,4,5范围,或的关系)
8、NOT IN #不在...之内
sql语句的分类:

线上服务器的安全:
1、不要用root连接
2、默认密码也修改掉(因为人家会用字典一个一个的破)
修改密码:去表中改
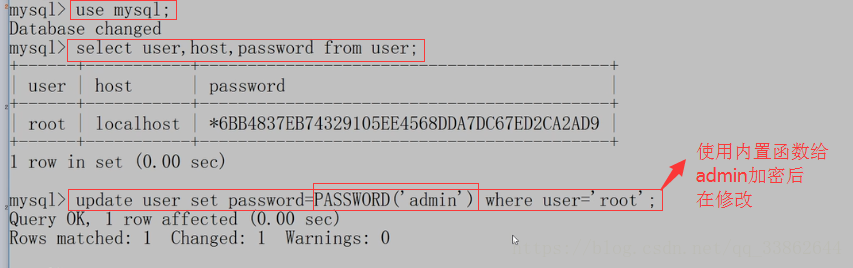
3、win的忘记密码:先停掉mysql
使用该命令,就不会查mysql自带的user表了,会给你开个新进程
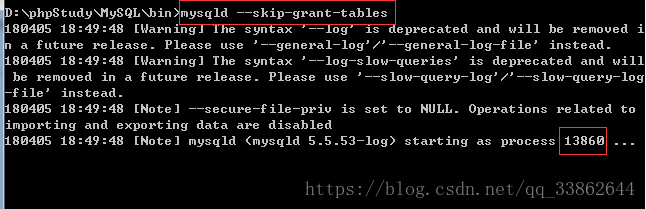
在打开一个cmd输入mysql进入mysql数据库
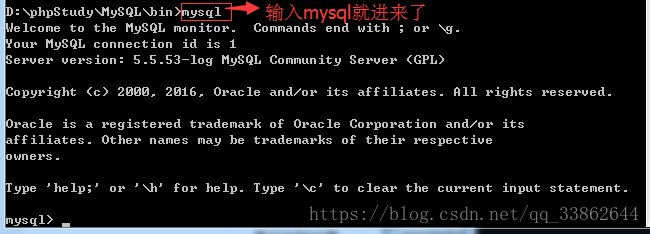
在通过sql语句更新,mysql自带的user表里的密码,在刷新权限
4、linux的忘记密码
-
修改MySQL的配置文件(默认为/etc/my.cnf),在[mysqld]下添加一行skip-grant-tables
-
保存配置文件后,重启MySQL服务 service mysqld restart
-
再次进入MySQL命令行 mysql -uroot -p,输入密码时直接回车,就会进入MySQL数据库了,这个时候按照常规流程修改root密码即可。
依次输入:
>use mysql; 更改数据库
>UPDATE user SET PASSORD =password("passwd") WHERE USER= 'root'; 重设密码
>flush privileges; 刷新MySQL的系统权限相关表,以防止更改后拒绝访问;或或者重启MySQL服务器
-
密码修改完毕后,再按照步骤1中的流程,删掉配置文件中的那行,并且重启MySQL服务,新密码就生效了。
5、限制登录ip
需求:如果代码和数据库不在同一个服务器中才需要改,小项目不需要改;或只允许自己的电脑连
查看mysql自带的数据库中的user表
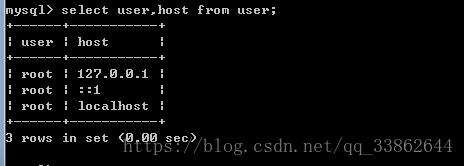
干掉后2条,登录就要加-h 而且只能是127.0.0.1才能访问
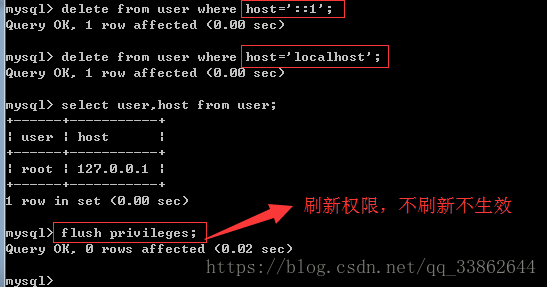
如果直接删掉不管用,就将root用户的host改成自己电脑的ip
普通用户的创建授权及权限回收


创建用户:
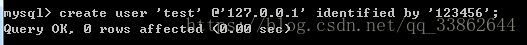
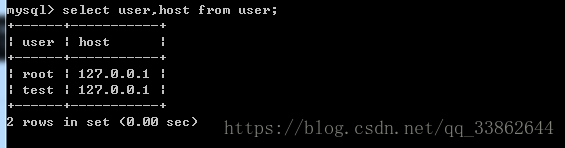

注意:
1、和权限相关的,每次做完都要刷新权限
2、%不安全,因为他对所有的ip都放行
给用户权限:

撤销权限:

查看权限:
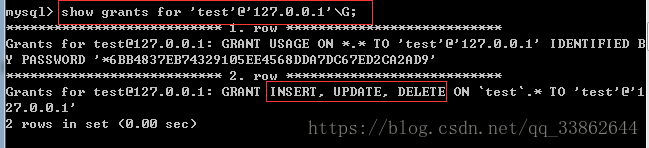
删除用户:

表的存储引擎
怎么理解这个引擎呢??
将mysql理解成显示器,引擎可以理解为cpu。因为mysql是开源的,这些引擎有好多都不是官方的,而是开源爱好者提供的。
为啥要弄这么多引擎啊??
不同的引擎,是解决不同的场景,是解决不同场景遇到问题的。
如 csv 对应的excel入库 用这个快还好

表锁:每次写操作都会锁整张表,这整张表就不能进行任何读、写操作了
行锁:每次写操作都会锁整行,这行记录就不能进行任何读、写操作了
sql_mode的模式
往MySQL数据库中插入一组数据时,出错了!数据库无情了给我报了个错误:ERROR 1365(22012):Division by 0;意思是说:你不可以往数据库中插入一个 除数为0的运算的结果。于是乎去谷歌了一番,总算是明白了其中的原因:是因为MySQL的sql_mode 模式限制着一些所谓的‘不合法’的操作。
解析
这个sql_mode,简而言之就是:它定义了你MySQL应该支持的sql语法,对数据的校验等等。。
一、如何查看当前数据库使用的sql_mode:
mysql> select @@sql_mode;
如下是我的数据库当前的模式:

二、sql_mode值的含义:
ONLY_FULL_GROUP_BY:
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么将认为这个SQL是不合法的,因为列不在GROUP BY从句中
STRICT_TRANS_TABLES:
在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做任何限制
NO_ZERO_IN_DATE:
在严格模式,不接受月或日部分为0的日期。如果使用IGNORE选项,我们为类似的日期插入'0000-00-00'。在非严格模式,可以接受该日期,但会生成警告。
NO_ZERO_DATE:
在严格模式,不要将 '0000-00-00'做为合法日期。你仍然可以用IGNORE选项插入零日期。在非严格模式,可以接受该日期,但会生成警告
ERROR_FOR_DIVISION_BY_ZERO:
在严格模式,在INSERT或UPDATE过程中,如果被零除(或MOD(X,0)),则产生错误(否则为警告)。如果未给出该模式,被零除时MySQL返回NULL。如果用到INSERT IGNORE或UPDATE IGNORE中,MySQL生成被零除警告,但操作结果为NULL。
NO_AUTO_CREATE_USER
防止GRANT自动创建新用户,除非还指定了密码。
NO_ENGINE_SUBSTITUTION:
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
另外还有一些,这里仅对我本地当前值做解释分析。。。。。
三、据说是MySQL5.0以上版本支持三种sql_mode模式:ANSI、TRADITIONAL和STRICT_TRANS_TABLES。
1、ANSI(默认)模式:宽松模式,更改语法和行为,使其更符合标准SQL。对插入数据进行校验,如果不符合定义类型或长度,对数据类型调整或截断保存,报warning警告。对于本文开头中提到的错误,可以先把sql_mode设置为ANSI模式,这样便可以插入数据,而对于除数为0的结果的字段值,数据库将会用NULL值代替。
将当前数据库模式设置为ANSI模式:
mysql> set @@sql_mode=ANSI;
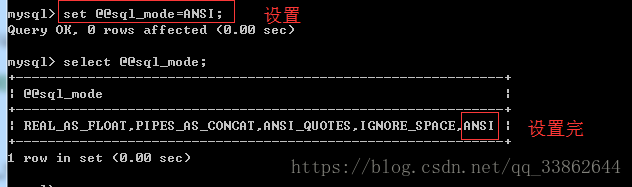
2、TRADITIONAL模式:严格模式,当向mysql数据库插入数据时,进行数据的严格校验,保证错误数据不能插入,报error错误,而不仅仅是警告。用于事物时,会进行事物的回滚。 注释:一旦发现错误立即放弃INSERT/UPDATE。如果你使用非事务存储引擎,这种方式不是你想要的,因为出现错误前进行的数据更改不会“滚动”,结果是更新“只进行了一部分”。
将当前数据库模式设置为TRADITIONAL模式:
mysql> set @@sql_mode=TRADITIONAL;
3、STRICT_TRANS_TABLES模式:严格模式,进行数据的严格校验,错误数据不能插入,报error错误。如果不能将给定的值插入到事务表中,则放弃该语句。对于非事务表,如果值出现在单行语句或多行语句的第1行,则放弃该语句。
将当前数据库模式设置为STRICT_TRANS_TABLES模式:
mysql> set @@sql_mode=STRICT_TRANS_TABLES;
没有最好与最坏的模式,只有最合适的模式。需要根据自己的实际情况去选择那个最适合的模式!!!
另外说一点,这里的更改数据库模式都是session级别的,一次性,关了再开就不算数了!!!
也可以通过配置文件设置:vim /etc/my.cnf
在my.cnf(my.ini)添加如下配置: [mysqld] sql_mode='你想要的模式'DTL事物控制语言
一条sql语句就是一个事务。事务可以保证一组sql语句,要么都成功,要么都失败。默认自动提交

注意:执行sql语句的时候,会默认提交(就给数据写到硬盘中了)。修改完是临时生效

多个事务,同时并发执行的例子:多人同时转账。
数据库编程--面向过程函数【存储过程】
把多条sql语句,写到一个函数中(它是一条或多条sql语句的集合)
作用:sql语句的复用(php中代码复用)。先定义,后调用
1、将sql结尾的;改成其他符号(防止冲突,将存储过程提前结束。因为你存储过程中也会用到分号)
delimiter /// #将sql结束符改成///
2、定义存储过程
语法:create procedure 相当于php的 public function
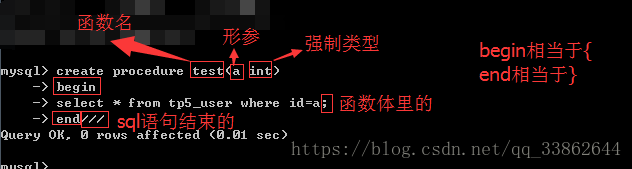
查看存储过程
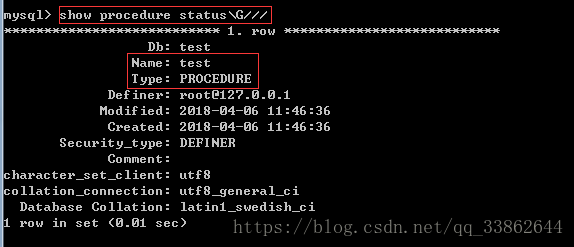
3、使用存储过程
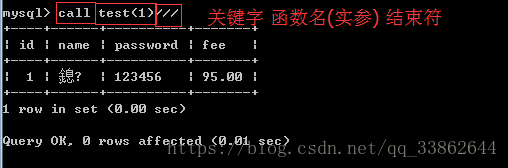
4、不想要了,直接删除

视图的创建删除及使用场景
主要作用:涉及到安全方面
场景1:别的公司想调用咱们的用户,就可以给他创建一个视图。他只能调用这个视图(调用我们想给他暴露的数据)
场景2:cto不想让开发知道更多的用户信息
场景3:新手不会写复杂的sql(如 连表啊,子查询啊),老司机就给他个视图就ok了,因为视图的后面就是sql语句
视图和存储过程的区别:
1、存储过程:中可以是各种sql语句,是方便我们自己使用
2、视图:中只能是select,是方便我们给外人使用,会生成一张表
总结:相当于是as后面得sql结果存到了test_view表中(show tables;就能看出来),然后使用视图的时候查test_view表
创建视图:
注意:as后面是sql语句,写不写where条件都可以。test_view(这里的字段名叫啥无所谓,带不能用''括起来,个数要和as后面输出的对上)

查看视图:
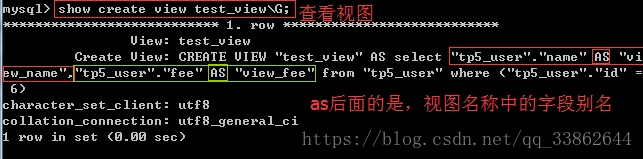
使用视图:
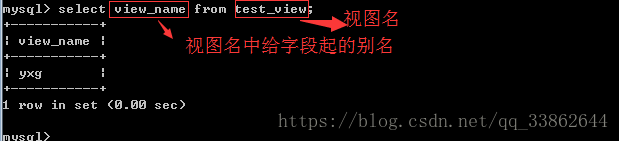
删除视图:

触发器

对某个(文章)表做了某些操作,它会触发另一些操作(统计表+1)
场景1:文章表每发送一篇文章,统计表中+1(创建一个触发器),删掉一篇文章-1(在创建一个触发器)
总结:相当于php框架中的钩子
1、准备数据,创建文章表和统计表
mysql> create table article( -> id int unsigned not null auto_increment primary key, -> title varchar(20) not null -> );
mysql> create table total_num( -> id int unsigned not null auto_increment primary key, -> type tinyint unsigned not null comment '1统计文章,2统计用户', -> num int unsigned not null -> );
先插入2条数据,不然他统计没法+1
insert into total_num (type,num) values(1,0);
insert into total_num (type,num) values(2,0);
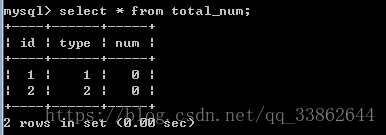
2、创建增加的触发器
往article表中插入数据
insert into article (title) values('woshi_title'); 查看total_num统计表
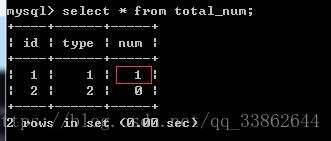
3、创建删除的触发器
mysql> create trigger delete_total_num after delete on article for each row -> begin -> update total_num set num=num-1 where type=1; -> end///
删除文章表的数据,触发删除触发器
delete from article where id=1;
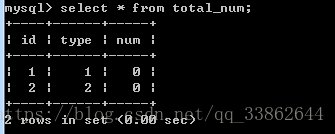
4、查看触发器:
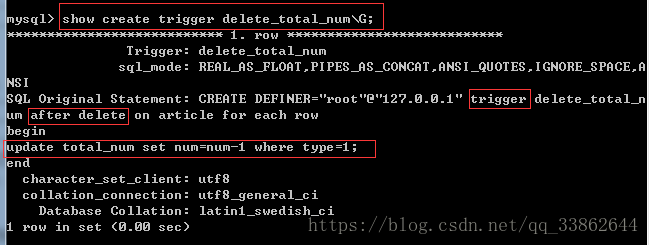
5、删除触发器:

mysql中的日志
MySQL中的日志包括:错误日志、二进制日志、通用查询日志、慢查询日志等等。
这里主要介绍下通用查询日志
通用查询日志:记录建立的客户端连接和执行的语句
在学习通用日志查询时,需要知道几个数据库中的常用命令:
1、 show variables like '%version%';
效果图如下:
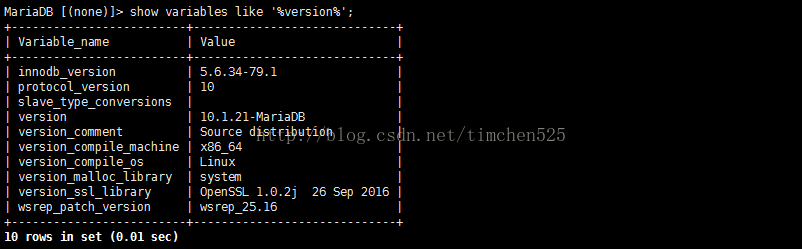
上述命令,显示当前数据库中与版本号相关的东西。
2、show variables like '%general%';

可以查看,当前的通用日志查询是否开启,如果general_log的值为ON则为开启,为OFF则为关闭(默认情况下是关闭的)。
3、 show variables like '%log_output%'; //查看当前日志输出的格式

可以是FILE(存储在数数据库的数据文件中的hostname.log),
也可以是TABLE(存储在数据库中的mysql.general_log)

问题:如何开启MySQL通用查询日志,以及如何设置要输出的通用日志输出格式呢?
开启通用日志查询: set global general_log=on;
关闭通用日志查询: set globalgeneral_log=off;
设置通用日志输出为表方式: set globallog_output=’TABLE’;
设置通用日志输出为文件方式: set globallog_output=’FILE’;
设置通用日志输出为表和文件方式:set global log_output=’FILE,TABLE’;
(注意:上述命令只对当前生效,当MySQL重启失效,如果要永久生效,需要配置my.cnf)
日志输出的效果图如下:
记录到mysql.general_log表中的数据如下(从连接客户端开始执行的所有指令):

记录到本地中的.log中的格式如下(找不到,不知道这日志生成在哪了):
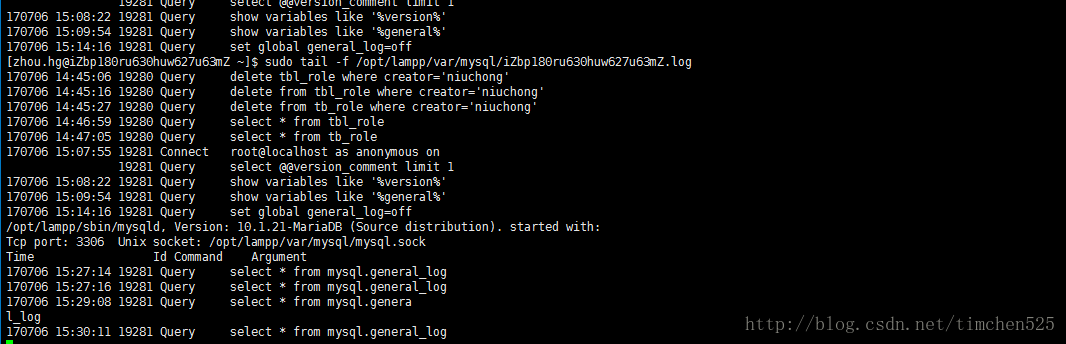
my.cnf文件的配置如下:
general_log=1 #为1表示开启通用日志查询,值为0表示关闭通用日志查询
log_output=FILE,TABLE#设置通用日志的输出格式为文件和表
4、在MySQL中有一个变量专门记录当前慢查询语句的个数:
输入命令:show global status like ‘%slow%’;

慢查询日志、优化
慢查询日志:记录所有执行时间超过long_query_time秒的所有查询或者不使用索引的查询
该日志可以写入文件或者数据库表,如果对性能要求高的话,建议写文件。超过1秒的就算慢查询了。
一般来说,慢查询发生在大表(比如:一个表的数据量有几百万),且查询条件的字段没有建立索引,此时,要匹配查询条件的字段会进行全表扫描,耗时查过long_query_time,则为慢查询语句。
1、首先查看慢查询日志是否开启
第1种:超过long_query_time时间的慢查询
注意:平常不要开,只有分析的时候才开(因为开启后sql语句需要往日志里写,也要耗时间)。

set global slow_query_log=on; //打开慢查询日志,临时生效,永久生效需要写在my.cnf中
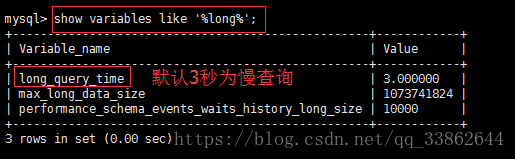
set long_query_time=0.2; //设置为200ms算慢查询。注意:设置这个参数的时候不要加global
第2种:不使用索引的慢查询

注意:如果只是将log_queries_not_using_indexes设置为ON,而将slow_query_log设置为OFF,此时该设置也不会生效,即该设置生效的前提是slow_query_log的值设置为ON),一般在性能调优的时候会暂时开启。
总结:俩种方式加一起,看下图这4个就够了

2、实际在学习过程中,如何得知设置的慢查询是有效的?
很简单,我们可以手动产生一条慢查询语句,
比如,如果我们的慢查询log_query_time的值设置为1,则我们可以执行如下语句:
select sleep(1);
该条语句即是慢查询语句,之后,便可以在相应的日志输出文件或表中去查看是否有该条语句。
3、看日志,找出执行时间超过200ms的慢查询sql
慢查询的日志记录myql.slow_log表中,格式如下:

慢查询的日志记录到hostname.log文件中,格式如下:
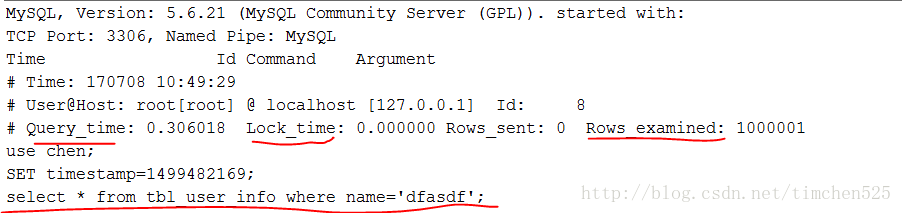
可以看到,不管是表还是文件,都具体记录了:
是那条语句导致慢查询(sql_text),
该慢查询语句的查询时间(query_time),
锁表时间(Lock_time),
以及扫描过的行数(rows_examined)等信息。
4、分析慢的原因
思路1:使用explain sql语句; 查看详细信息做对比;
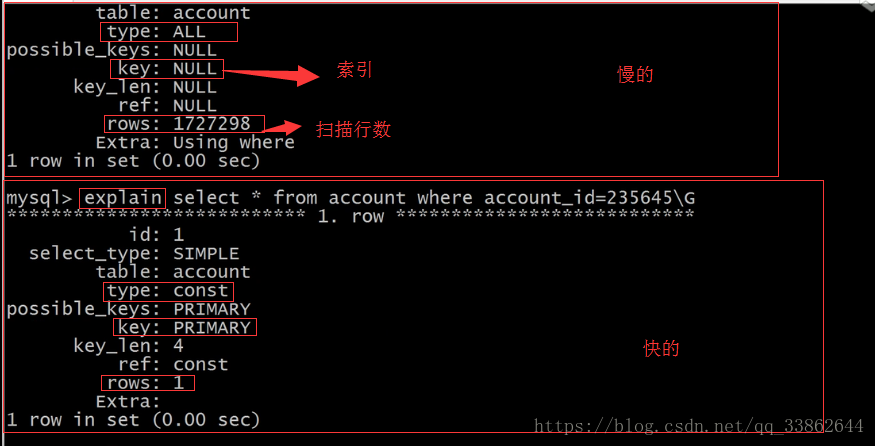
思路2:
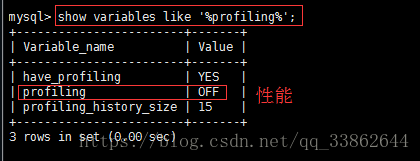
mysql> set profiling=on; //打开性能
执行一遍慢的sql语句
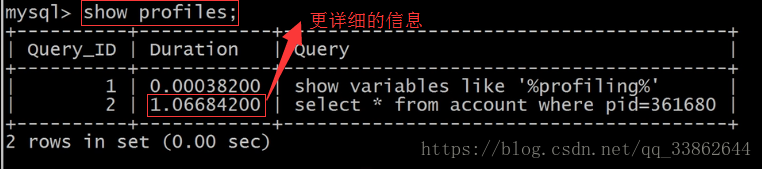
然后输入 show profiles; 查看执行过程
思路:不知道怎么优化,直接给时间长的粘百度上,看别人咋解决的
案例1:如果执行过程中缓存锁(xxxxx query cache lock)太耗时,很有可能缓存出问题了,这时候就给缓存关掉
案例2:不要在字段或字段的值上做运算(这样也索引会失效)

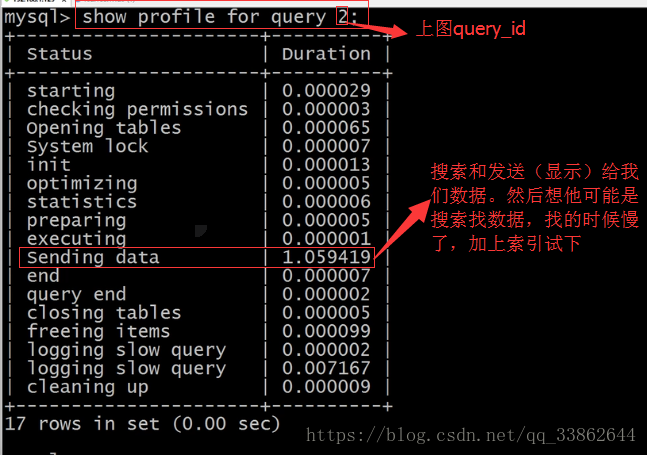
starting //开启
checking permissions //检测权限
opening tables //打开表
system lock //表锁、行锁的那个锁
init //初始化
optimizing //
statistics //
preparing //预编译(这时候就体验出存储过程了,存储过程会提前预编译好,直接调用执行即可)
executing //编译完执行
sending data //搜索数据并返回(发送给我)
end //结束
query end //
closing tables //关闭表
freeing items //
logging slow query //如果发现该条sql慢,会记录到慢日志中
cleaning up //
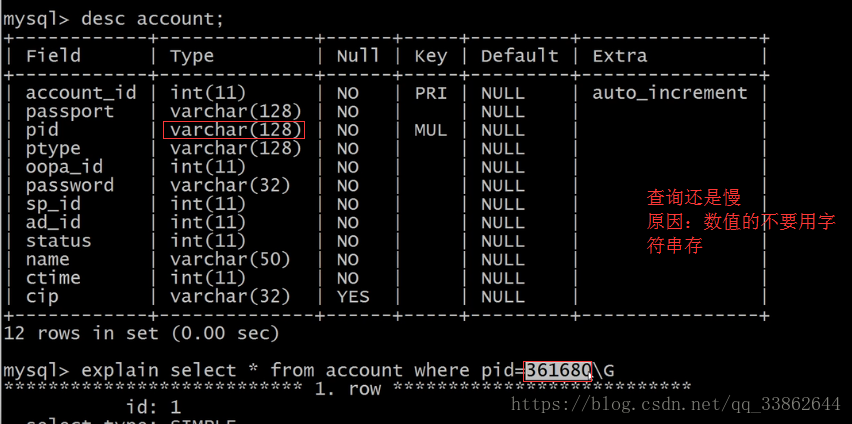
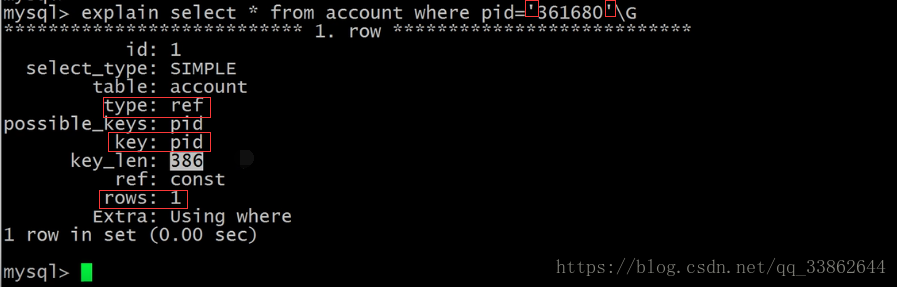
对应了:数据类型是字符串,查询时不加引号,索引会失效
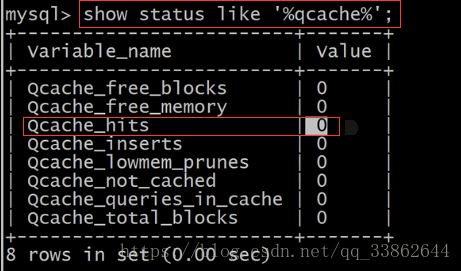
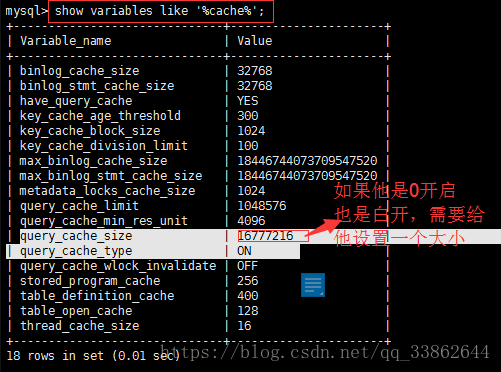
数据库缓存
缓存默认是开启的
看缓存命中率